细说iOS代码签名(四)
导航
- 一口气读完,大约需要40-60分钟
- 分步阅读
- 细说iOS代码签名(一):签名的作用及原理
- 细说iOS代码签名(二):开发者证书、Entitlements、Provisioning Profile
- 细说iOS代码签名(三):签名的过程及代码签名的数据结构
- 细说iOS代码签名(四):签名校验、越狱、重签名
0x06 签名的校验
签名的校验并非一次性完成,在安装、启动、和运行时有着不同的校验规则。
Read on →签名的校验并非一次性完成,在安装、启动、和运行时有着不同的校验规则。
Read on →万事具备,只欠东风,已经具备了签名所需的所有条件,接下来就可以开始研究签名的具体过程了。
Read on →在了解了签名和证书的基本结构之后,我们来研究一下iOS的开发者证书,它是开发过程中必不可少的东西,相信大家都有接触。众所周知,iOS设备并不能像Android那样任意地安装app,app必须被Apple签名之后才能安装到设备上。而开发者在开发App的时候需要频繁地修改代码并安装到设备上进行测试,不可能每次都先上传给Apple进行签名,因此需要一种不需要苹果签名就可以运行的机制。
Read on →数字签名其实跟我们手写的签名类似,代表一个特定的主体(签名者)对特定内容(被签名数据)的署名和认可,签名是对信息发送行为真实性的有效保障。数字签名在很多领域都有应用,iOS的代码签名正是其中最典型的一种,我们可以先尝试分析一下iOS上代码签名的目的和好处。
Read on →2008年苹果发布iOS2.0时引入了强制代码签名(Mandatory Code Signing)技术,为了能够严格控制设备上能够运行的代码,这为iOS设备的安全性和苹果的AppStore生态奠定了坚实的基础。作为iOSer总是要跟代码签名打交道的,相信大部分人对代码签名都是一知半解,本文将会由浅入深,深挖代码签名的内部细节。
苹果在WWDC 2015大会上引入了bitcode,随后在Xcode7中添加了在二进制中嵌入bitcode(Enable Bitcode)的功能,并且默认设置为开启状态。很多开发者在集成第三方SDK的时候都被bitcode坑过一把,然后google百度一番发现只要关闭bitcode就可以了,但是大部分开发者都不清楚bitcode到底是什么东西。这篇文档将给大家详细地介绍与bitcode有关的内容。
研究bitcode之前需要先了解一下LLVM,因为bitcode是由LLVM引入的一种中间代码(Intermediate Representation,简称IR),它是源代码被编译为二进制机器码过程中的中间表示形态,它既不是源代码,也不是机器码。从代码组织结构上看它比较接近机器码,但是在函数和指令层面使用了很多高级语言的特性。
LLVM是一套优秀的编译器框架,目前NDK/Xcode均采用LLVM作为默认的编译器。LLVM的编译过程可以简单分为3个部分:
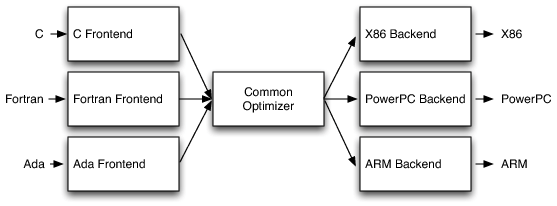
在这个体系中,不同语言的源代码将会被转化为统一的bitcode格式,三个模块可以充分复用,防止重复造轮子。如果要开发一门新的x语言,只需要造一个x语言的前端,将x语言的源代码编译为bitcode,优化和后端的事情完全不用管。同理,如果新的芯片架构问世,则只需要基于LLVM重新写一套目标平台的后端,非常方便。
既然bitcode是代码的一种表示形式,因此它也会有自己的一套独立的语法,可以通过一个简单的例子来一探究竟,这里以clang为例,swift的操作和结果可能稍有不同。
本文所涉及的内容可以自行操作,也可以直接下载我写这篇文章时保存的副本
先编写一段helloworld代码(test.c):
1 2 3 4 5 | |
通过以下命令可以将源代码编译为object文件:
1 2 3 | |
其实,这个命令同时完成了前端、优化、后端三个部分,可以通过 -emit-llvm -c 将前端这一步单独拆出来,这样就可以看到bitcode了:
1 2 3 4 5 6 7 8 9 | |
bitcode文件使用后缀名.bc表示,可以看到,将bitcode文件作为clang的输入,编出的object文件跟直接编源代码是相同的。然后在来看一下bitcode文件:
1 2 3 4 5 6 7 8 9 10 11 | |
通过hexdump可以看出这个文件并非文本文件,全是乱码,这样的文件是很难分析的。其实LLVM提供了llvm-dis/ llvm-as 两个工具,用于将bitcode在二进制格式和可读的文本格式之间进行相互的转化,但遗憾的是Xcode的编译器工具链中并没有附带这个命令,因此只能另寻他法。
470 points
1 2 3 4 | |
I didn’t have enough time to solve this challenge since I’m busy at work. It’s a pity that my team didn’t, neither. But I have to say it’s a very challenging one. Combination of crypto and SQL injection.
It seemed to be a web challenge because the entrance was a website. So let’s start with HTTP requests and responses. In the source code of the page, a path to secret login page was commented.
1 2 3 4 5 6 7 8 9 | |
The login page set a cookie like this(using httpie)
1 2 3 4 5 6 7 8 9 10 11 | |
It’s easy to say that the cookie is two parts of base64 encoded string concatenated by a |.
1
| |
Different cookies was returned when repeating the same request. Modify the tail of the cookie will got a message Error has occur from decrypt.., but the head won’t.
When we are doing security tests, we always change our IP address to bypass some security strategies. The easiest way to change IP is using a proxy.
Some websites can provide proxy IPs, but none of them can ensure the healthy of those proxy hosts. It’s a horrible thing to check them one by one by hand when you wanna got one. So we can crawl these websites and test every proxy IP automatically.
The project is hosted at https://github.com/xelzmm/proxy_server_crawler.
Proxy Server Crawler is a tool used to crawl public proxy servers from proxy websites. When crawled a proxy server(ip::port::type), it will test the functionality of the server automatically.
Currently supported websites:
Currently supported testing(for http proxy)
念大婶在博客中介绍了两种方法,用于保护代码逻辑,对抗逆向分析
如果用了第二种方式,将函数改用c实现,虽然通过class-dump得不到有价值的信息,但通过nm命令或者IDA/Hopper等工具仍然能从符号表中找到这些c函数以及衍生出的一些静态变量。针对这种情况,我们还是可以通过宏定义的方式,将这些c的标识符(函数名、变量名)替换为随机字符串。
举个例子:
1 2 3 4 5 6 7 8 9 | |
nm检查符号表,结果如下
1 2 3 | |
说明宏替换对于c的标识符同样有效。但是要一个个手动去define,感觉是要累死的节奏。如果能通过一个脚本,自动从源代码里把所有的标识符声明提取出来,生成一个头文件就好了。可以考虑几种方案:
很显然,前两种方案都很繁琐,不好维护。并且如果我要做一个library给第三方使用,必然要暴露一些接口不能被混淆,只有第三种方式可以灵活地选择那些需要混淆哪些不需要,而这种方案实现起来也最简单。最终实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
使用asm label语法的好处是,只需要将符号的声明标记出来进行替换即可, 不需要对该符号的引用进行标记和替换。如果要混淆已经完成的代码,这一点非常省时省力。